Token Discipline: Spend AI Tokens on Work, Not Narration
AI costs are shifting from prompt cost to output discipline.
For chat demos, a verbose answer feels harmless. For production agents, the same habit compounds into repeated summaries, pasted logs, mid-task narration, and explanations nobody asked for.
That is not just aesthetic waste. It is billable output.
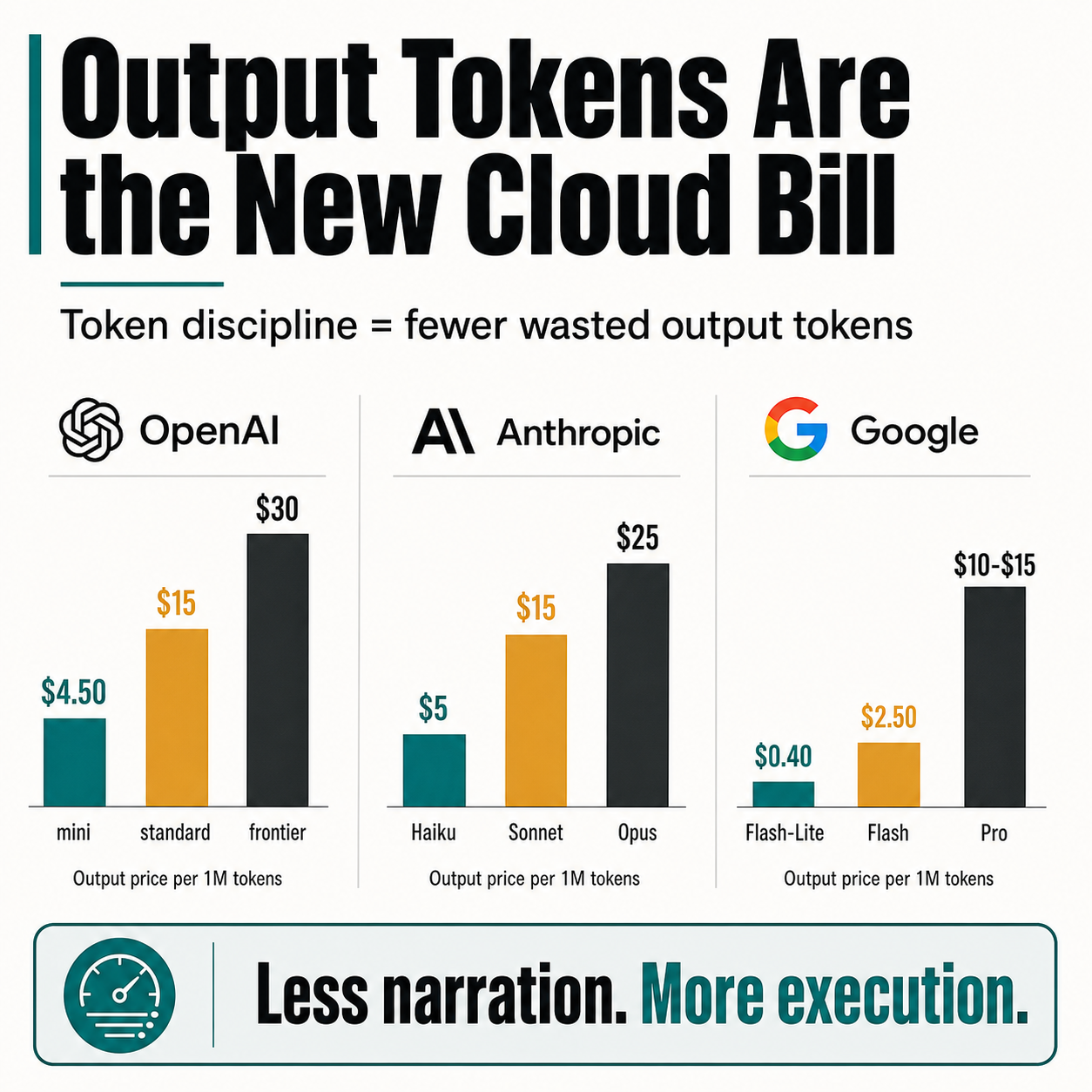
The Price Ladder
Current standard output-token pricing per 1M tokens shows how quickly the cost grows as teams move toward stronger models:
| Provider | Lower-cost tier | Mid tier | Frontier tier |
|---|---|---|---|
| OpenAI | GPT-5.4 mini: $4.50 | GPT-5.4: $15 | GPT-5.5: $30 |
| Anthropic | Claude Haiku 4.5: $5 | Claude Sonnet 4.6: $15 | Claude Opus 4.7: $25 |
| Gemini 2.5 Flash-Lite: $0.40 | Gemini 2.5 Flash: $2.50 | Gemini 2.5 Pro: $10-$15 |
The point is not that any one provider is expensive. The point is that output verbosity has a measurable price, and that price rises exactly where teams want the most capable agents.
The Rule I Added
I added this rule to my agent instructions:
Token discipline: no user-facing prose unless needed to complete the requested action. Avoid mid-task updates unless blocked or coordination-critical. Act from context; ask only when needed. End with compact
what changed / how / checkswhen applicable. Omit logs, diffs, and repeated context unless requested.
This does not make an agent less helpful.
It makes the agent spend more of its budget on doing the task.
How It Saves Tokens
The biggest savings come from cutting output that does not change the outcome:
- No routine progress narration while the agent is already working.
- No pasted logs unless the user needs the raw evidence.
- No repeated context that already exists in the thread.
- No explanation before action when the next step is obvious.
- A compact end summary so the user still gets closure without reading a transcript.
If an agent avoids 1M unnecessary output tokens, the savings can be roughly $30 on GPT-5.5, $25 on Claude Opus 4.7, or $10-$15 on Gemini 2.5 Pro.
That is the practical framing: not “make AI terse,” but “spend tokens where they create value.”
Less narration. More execution.
Sources: